
컨테이너
- XXX의 라이프 사이클을 관리
- e.g. Servlet Container, IoC Container, Bean Container
- 생성 - 운영 - 제거까지 생애 주기 관리 👉 격리 필요
특징
- 우리는 이 컨테이너 안에 무엇이 있는지 알 수 X
- 컨테이너 안의 대상은 컨테이너가 곧 세상이라고 생각함
이점
- 컨테이너 안에 무엇이 있든
컨테이너 단위로 사고 O - 컨테이너 단위로 적재하기 때문에 다른 컨테이너에 영향 X, OS를 새로 시작할 필요도 X
컨테이너는 프로세스를 관리
프로세스
- 실행 중인 프로그램
- 프로그램 실행 시에 필요한 명령 + 정보 조합의 오브젝트
- 프로그램이 OS에 의해 실행되는 단위
- e.g. HDD 등 저장장치에 있는 프로그램을 실행하면, 실행할 때 필요한 명령 + 정보 등을 메모리에 적재함
- 1개의 CPU는 1개의 프로세스 작업을 수행할 수 있음
- 일반적으로 CPU는 20ms 정도 프로세스 작업을 수행한 후, 대기하고 있는 다른 프로세스 작업을 수행함
- 프로세스를 종료하면, 메모리 등의 자원을 반납함
컨테이너는 프로세스를 추상화
- 컨테이너는 프로세스의 생성, 운영, 제거까지 생애 주기를 관리함 👉 이때 필요한 건
격리
무엇을 격리할까?
- 컨테이너 안의 프로세스는 제한된 자원 내에서 제한된 사용자만 접근할 수 있음
- 컨테이너는
Host OS의 시스템 커널을 사용함- 이 점이 가상 머신과 컨테이너의 차이
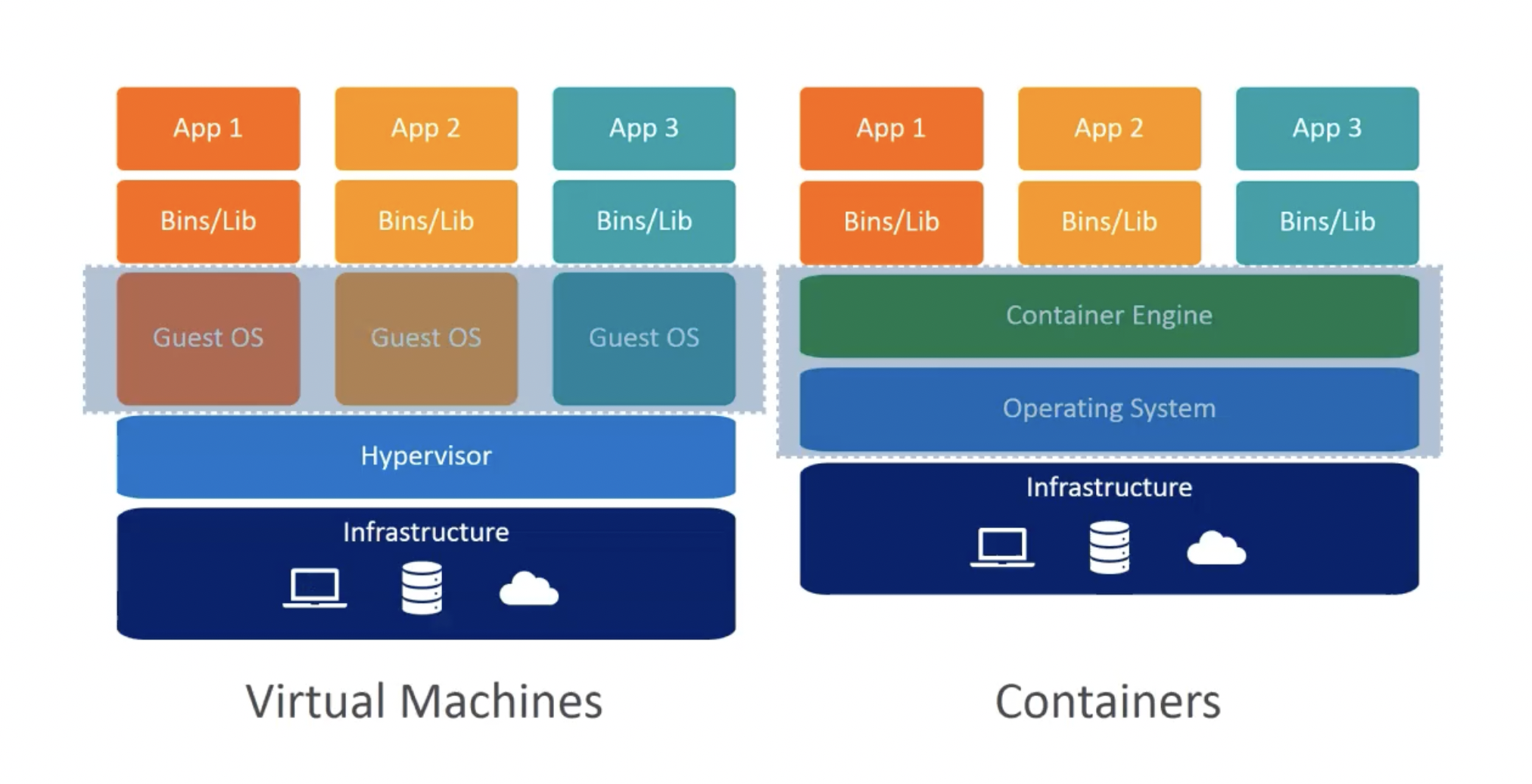
- 그러나, 파일 시스템은 다름
chroot👉 루트 파일 시스템을 강제로 인식시켜 프로세스를 실행함
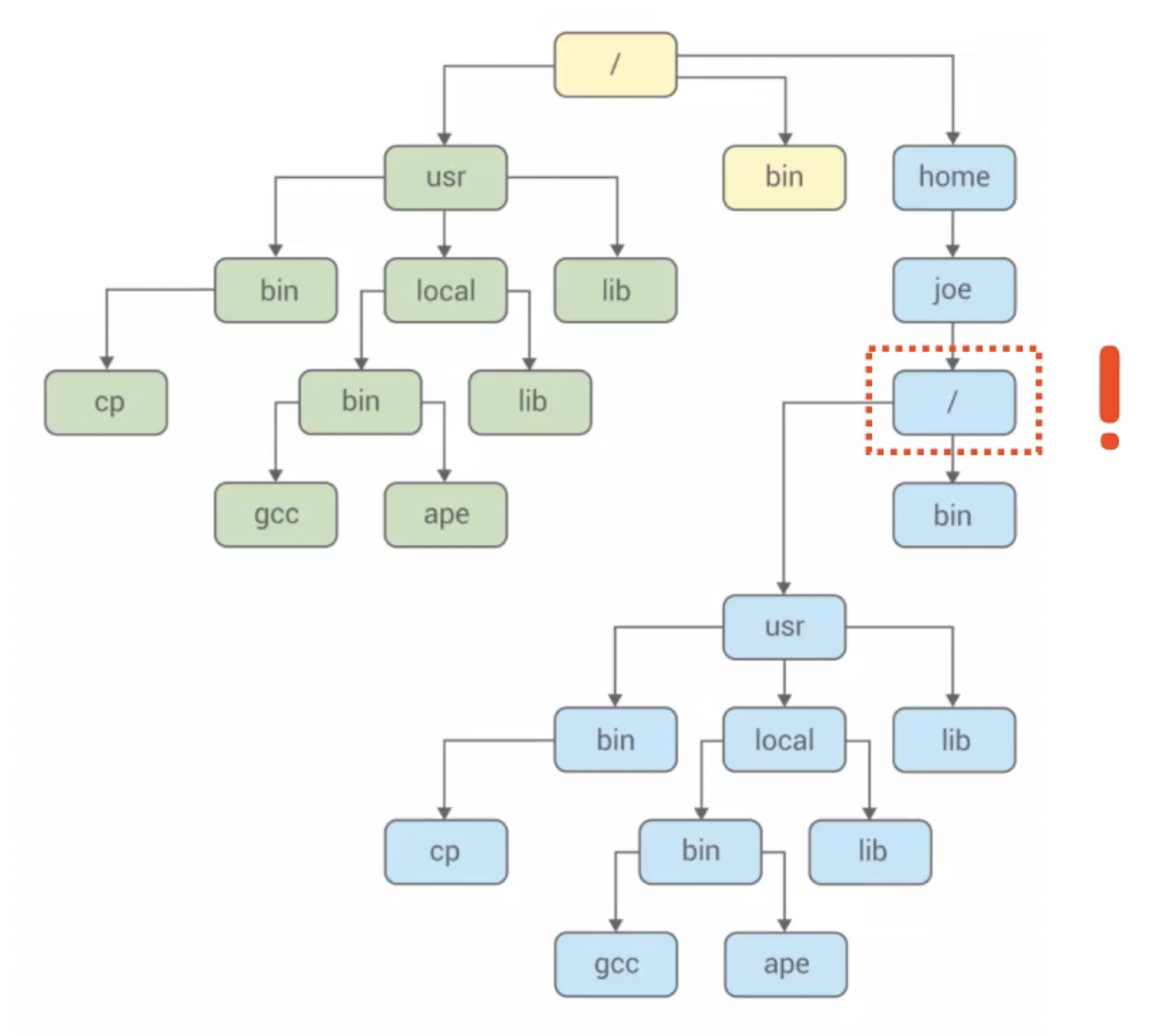
- 격리?
- 별도의 공간에 별도의 루트를 지정하고,
너는 여기서부터 루트야!라고 생각하게끔 함 - 컨테이너 안이 곧 세상이라고 인식하기 시작함
- 별도의 공간에 별도의 루트를 지정하고,
Host OS는 컨테이너를 어떻게 바라볼까?
- e.g. Nginx를 직접 실행 vs 컨테이너 안에서 실행
- Host OS에게는
동일한Nginx Process임
- Host OS에게는
우리가 컨테이너를 사용하는 이유는 무엇일까?
- 컨테이너 단위로 사고
- 각 프로세스의 라이프 사이클을 관리하기 위함
컨테이너 안의 프로세스가 다른 프로세스와 통신하려면 어떻게 해야 할까? 격리가 돼있는데?
컨테이너 네트워크
- 컨테이너의 본질은 격리
- 어떻게 다른 컨테이너와 통신이 가능할까?
컨테이너들의 위치를 아는 녀석이 있겠지?
컨테이너를 생성하면?
- 독자적인 파일 시스템이 하나 생성됨
- 이때,
네트워크 인터페이스도 하나 생성됨
컨테이너 네트워크를 보면?
- 컨테이너에 MAC Address, IP Address 할당 O
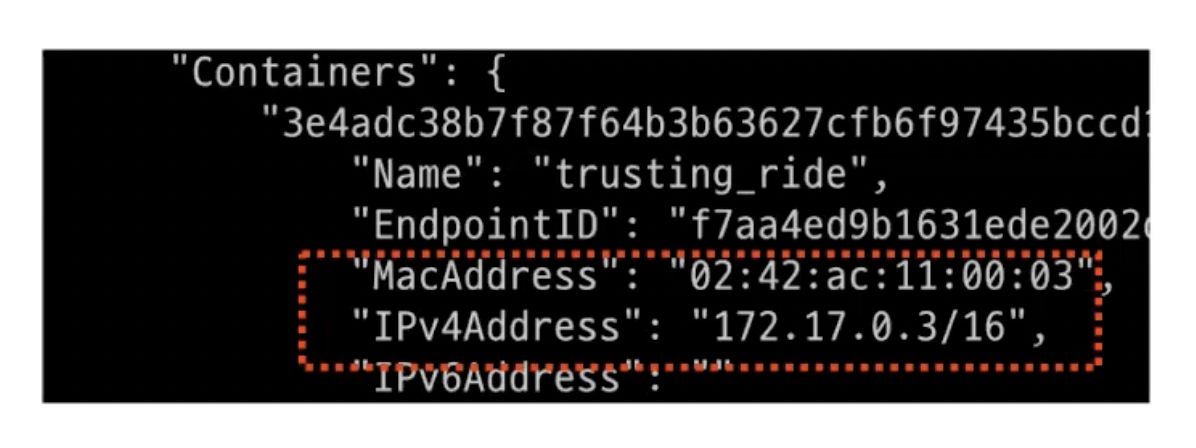
컨테이너 라우팅 테이블을 보면?
- 모르는 대역인 경우 172.17.0.1(default)로 보내라고 설정되어 있음
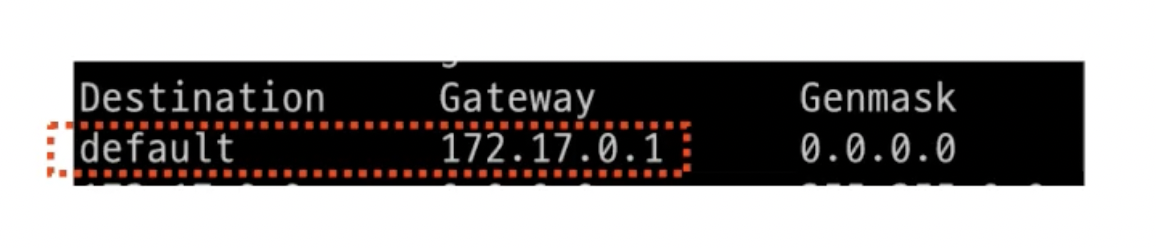
- 172.17.0.1은 Gateway IP Address인 것을 알 수 있고, 이 네트워크는 Driver로 bridge를 활용한다고 나와 있음
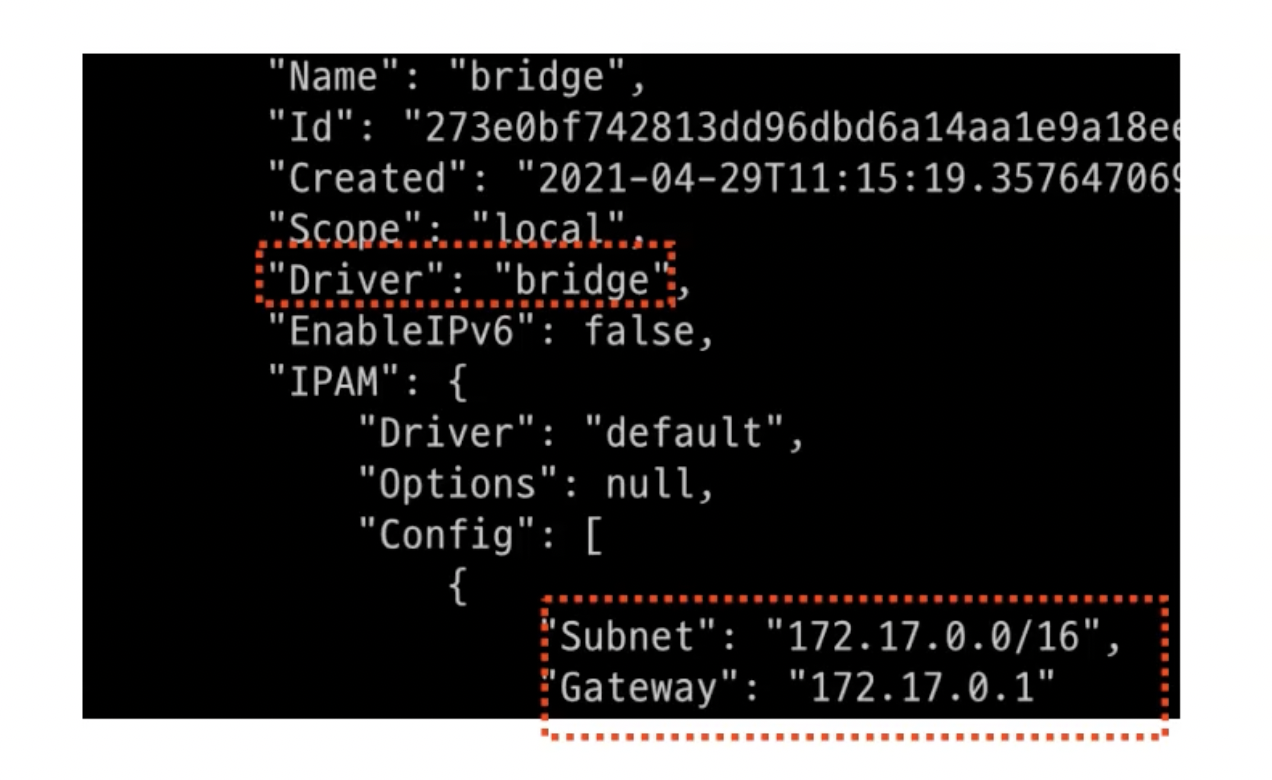
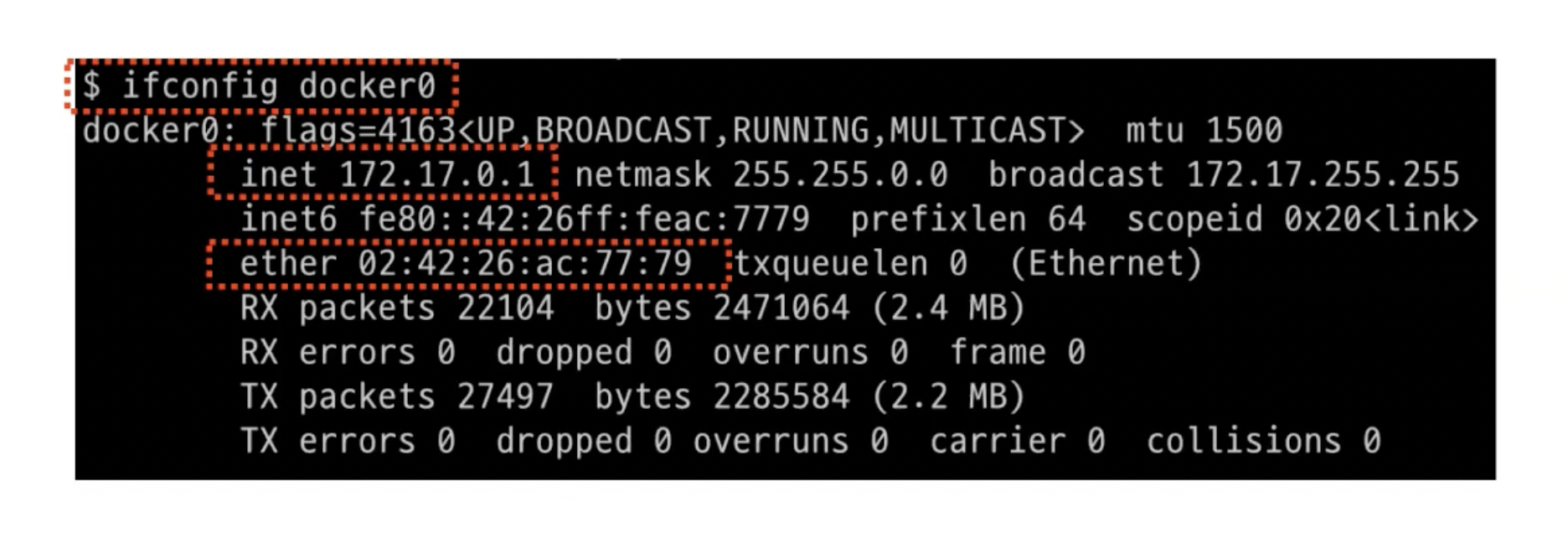
Host OS에서 확인하면?
- 172.17.0.1은
docker0라는 녀석이 점유하고 있음
정리하면?
- 컨테이너끼리 통신할 때, docker0는 bridge(like Switch) 역할을 함
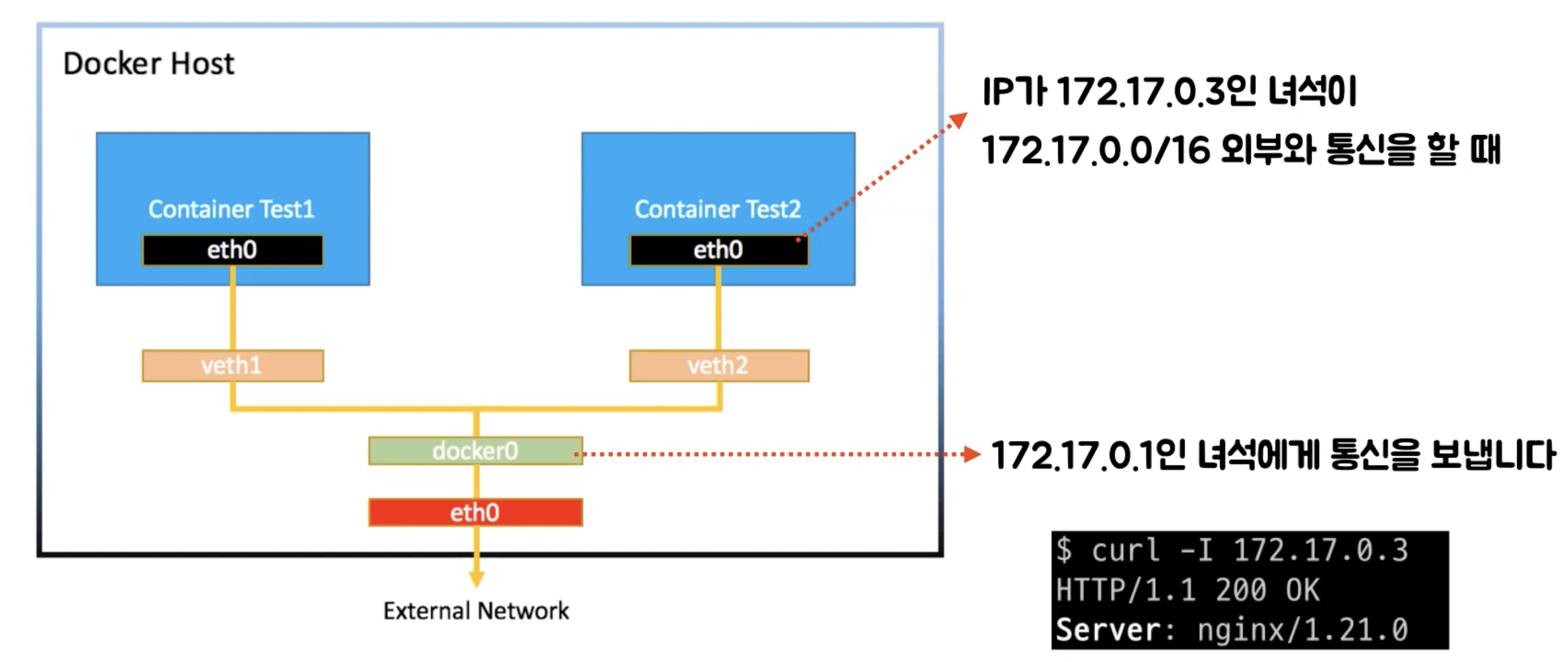
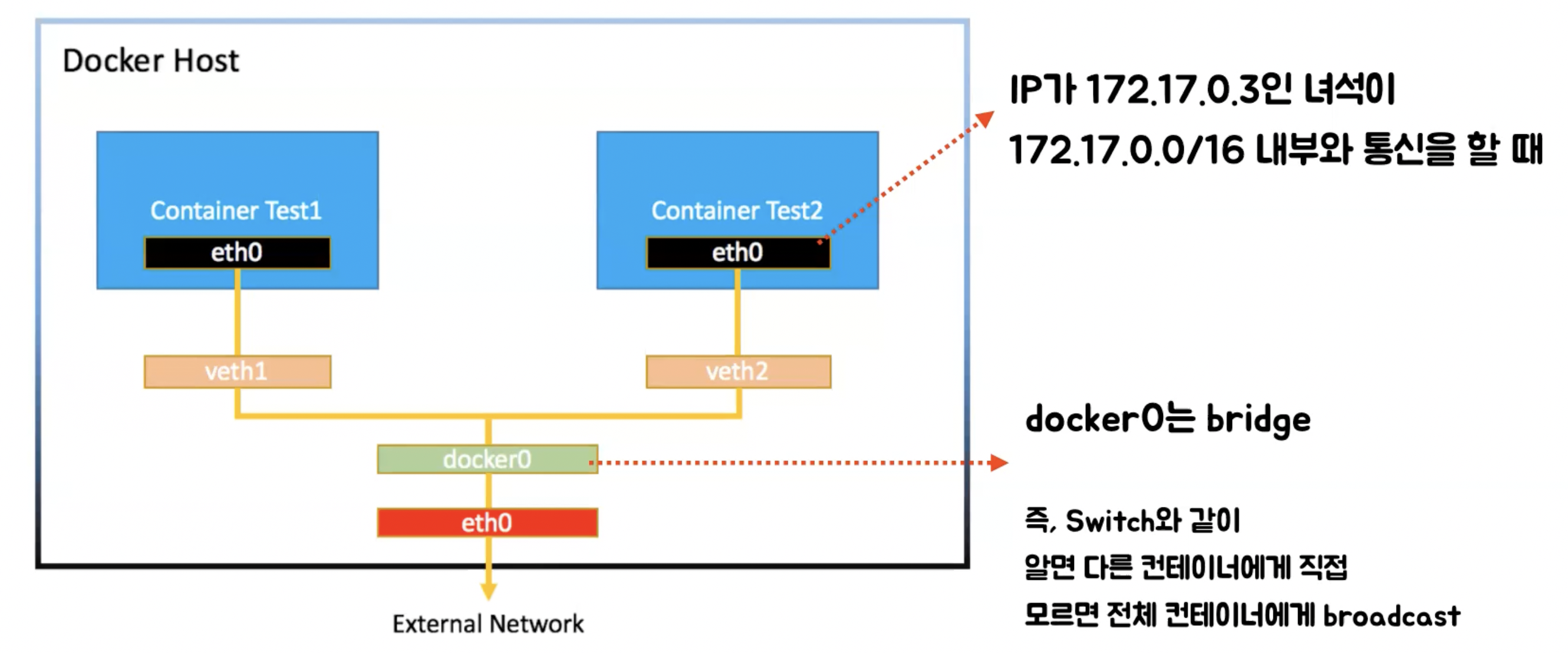
- 즉, 컨테이너 네트워크 내에서는 docker0를 통해 통신함
- 이게 아닌 대역대에서는 docker0를 통해 연결되어 있는 eth0(Ethernet)으로 보냄
결론적으로?
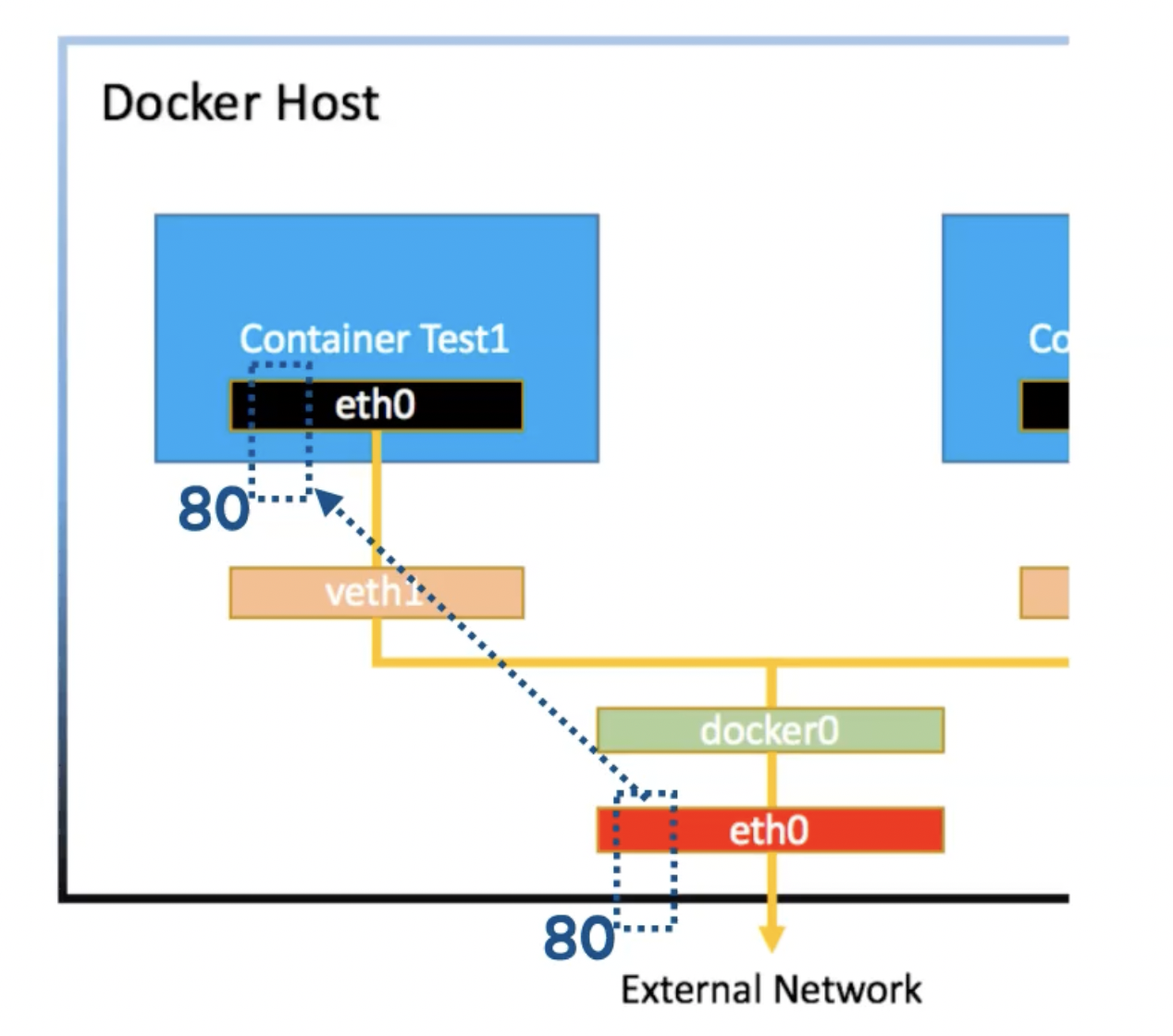
- 컨테이너를 생성하면 veth이 생성되고, 컨테이너 내의 eth0와 연결됨
- 컨테이너들의 veth은 docker0를 통해 컨테이너간 통신함
- 컨테이너는 Gateway인 docker0를 거쳐 외부와 통신함
포트포워딩을 사용하는 이유는 무엇일까?
- 아래 두 문제를 해결하기 위해 활용함
- 우리는 컨테이너의 IP Address를 확인하기 어려움
- 외부로부터 오는 요청은 Host의 물리적인 네트워크 인터페이스로 옴
포트포워딩
- e.g. 우리 인스턴스는 192 대역대를 사용하고 도커 컨테이너는 172 대역대를 사용하는 경우
- 다른 인스턴스에서는 172 대역대로 통신 X
- 우리 인스턴스의 특정 포트로 요청하면 도커 컨테이너의 특정 포트로 연결되게 구성
- 다른 인스턴스에서 통신이 가능해짐
1
$ docker run -d -p {host_port_number}:{docker_container_port_number} {process}
- e.g.
docker run -d -p 80:80 nginx하는 경우- Host의 80 포트 번호를 사용하는 소켓 파일과 도커 컨테이너의 80 포트 번호를 사용하는 소켓 파일을 연결함
컨테이너는 어떻게 사용할까?
- Docker 명령어
- Docker
- Images
- Docker Registry
- Dockerfile
- Container
- Backup
- Docker Daemon
- 사용자가 명령어를 입력하면 도커 데몬의 API를 호출함 👉 도커 데몬이 띄워져 있어 API 요청을 보내는 것
- 우리가 요청하는 이벤트는 도커 데몬에서 확인할 수 있음
- Docker Image
- 2가지 방식이 있음
- Docker Registry(like Github): 저장소에 있는 도커 이미지 사용
- 도커는 여러 레이어를 합쳐 파일 시스템을 이룸 👉 하나의 파일이 X
- Union File System
- 애플리케이션 코드가
git commit들이 모여 이루어지듯 컨테이너도docker commit들이 모여 이루어짐
- Dockerfile: 직접 도커 이미지 빌드
- 애플리케이션 코드가 빌드한 후 실행되듯 컨테이너도 빌드한 후 실행됨
- Docker Registry(like Github): 저장소에 있는 도커 이미지 사용
- 2가지 방식이 있음
- Docker Container
- 도커 이미지에 명세된 내용을 바탕으로 도커 컨테이너를 실행함
- 도커 컨테이너의 변경사항을 commit할 수도 있음
- 우리가 애플리케이션 코드를 Git으로 형상 관리하는 것처럼 도커 이미지도 마찬가지임
- 도커 이미지는
실행할 프로세스를 코드화해뒀다고 생각하면 됨
컨테이너를 제거하면 어떻게 될까?
- 도커 이미지는 읽기 전용
- 즉, 컨테이너를 제거하면 메모리에서 사라짐 👉 영속적인 데이터를 다룰 수 X
영속성 데이터는 어떻게 해야 할까?
- 컨테이너 자체는 상태가 X
- 상태를 결정하는 데이터를 외부로부터 제공받게 구성 (+ 볼륨 마운트 ?)
성능 테스트
서비스 상태를 어떻게 진단할까?
- USE 방법론
- 에러 로그를 확인
- 사용률, 부하 등의 요약 정보로 피해자를 파악
- 스냅샷으로 원인 파악
- 사용자 수가 많지도 않은데 CPU 사용률이 떨어지지 않을 때
- 특정 요청을 했는데 응답이 없을 때
⬇️
- RUNNABLE 상태면서 지속 시간이 긴 Thread가 없는지
- Lock 처리가 제대로 되지 않아 문제가 발생하고 있지는 않은지
서비스의 성능은 어떻게 확인할까?
- 상태 vs 성능 👉 다른 개념
- 여러 단계로 확인 가능
- 브라우저로 직접 QA하는
전구간 테스트 - webpagetest 등의 도구로
인터넷 구간 테스트 - 부하 테스트로
(브라우저 렌더링을 제외한) 전구간 테스트
- 브라우저로 직접 QA하는
웹 성능 테스트
- 성능의 개선 or 저하
- 수익에 직접적인 영향을 줌
- 사용자 트래픽이 많은 페이지, 가장 중요한 페이지가 무엇인지 파악
- 모든 페이지에 대해 성능을 최적화할 수 X, 따라서 여기에 맞춰 성능을 개선하는 게 중요함
- 경쟁 사이트 or 유사 사이트의 성능 조사
웹 요청 시 성능에 영향을 주는 요소는 무엇이 있을까?
- HTML, CSS, JS, 이미지, 웹 폰트 등
webpagetest
🪐 주로 웹 서버에 영향을 받는 지표들
- 해당 지표들이 우수하면?
- CDN 덕분에 가까운 곳에서
- keep-alive 설정으로 connection을 재사용하고
- 캐싱으로 요청 수를 최소화하며
- gzip 압축을 통해 각 리소스의 전송 인코딩을 최적화하고
- 이미지 압축을 통해 패킷 사이즈를 줄여
- 네트워크 비용을 절감할 수 있음
- 이 부분은 웹 서버의 설정을 변경해서 개선할 수 있는 포인트

🪐 정적 컨텐츠와 네트워크 상태에 영향을 받는 지표들
- 사용자 경험에 직접적인 영향을 줌
- 해당 지표들을 높이려면?
- 즉, 사용자 경험을 개선하려면?
- gzip 압축을 하거나
- CSS, JS 지연 로딩을 하거나
- 불필요한 JS를 제거하여
- 각 정적 리소스의 전송 비용을 절감할 수 있음
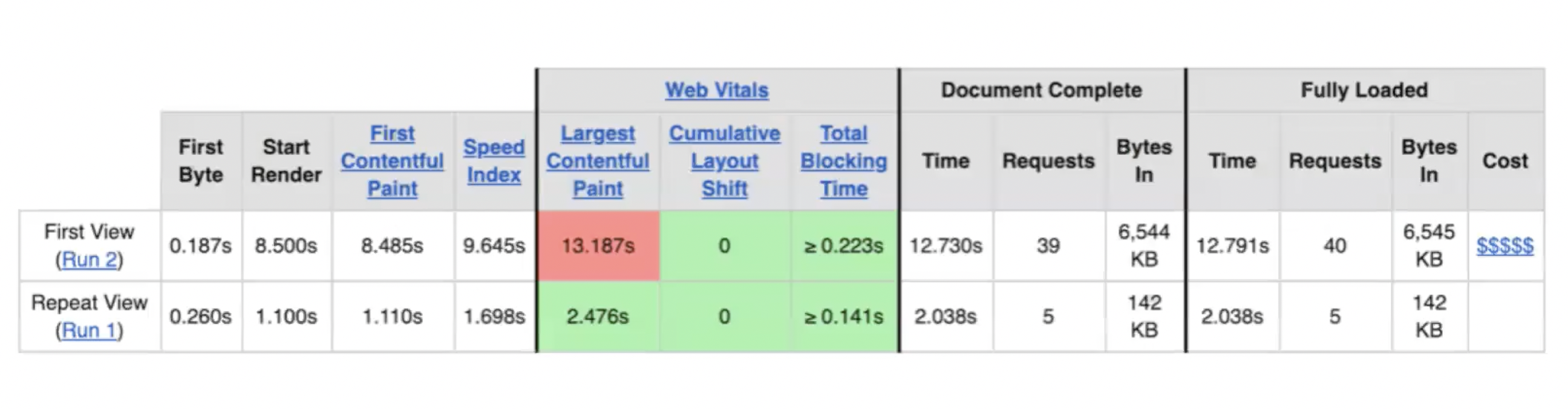
- 결국 네트워크 전송 비용을 줄일 수 있는 방법
- CDN 사용
- keep-alive 설정
- 캐싱 설정
- gzip 압축
- 이미지 압축
- 불필요한 작업 지연 로딩
- 불필요한 다운로드 제거
- 스크립트를 병합하여 요청 수 최소화
- 성능 개선, 클린 코드
- 끝을 바라보고 하는 게 X
- 어느 정도까지 허용 가능한지 목표를 정해야 함
부하 테스트
- API 서버의 성능을 어떻게 체크할까?
장애 내성을 가진 서비스는 어떻게 만들까?
- 아래 두 포인트를 확인하기 위해 테스트함
- 현재 시스템이 어느정도의 부하를 견디는지
- 한계치에서 병목이 발생하는 지점은 어디인지
한계치를 확인하면?
- 우리 서비스가 어느 정도 트래픽까지는 괜찮은지
- 한계점을 넘어설 때 어떤 증상이 나타나는지
- 장애 발생 시에 어떻게 대응하고 복구해야 할지
계획할 수 있음
병목을 확인하면?
- 어떻게 개선해야 할지
계획할 수 있음
- 가용성(Uptime)
- 가용률
- 시스템이 서비스를 정상적으로 제공할 수 있는 상태
- e.g. 1대의 서버에 문제가 생겨도 사용자는 인지 못할 수 있음
- 가용성을 높이기 위해서는 단일 장애점(SPOF)를 없애고,
확장성있는 서비스를 만들어야 함 - 가용성 👉 단일 장애점이 있는지? 생각하면 됨
- 단일 장애점(SPOF)
- e.g. 서버를 1대로 구성한다 하면?
- 서버 장비에 장애가 발생할 경우
- 애플리케이션 서버에 장애가 발생할 경우
- DB 서버에 장애가 발생할 경우
- 이런 상황에 서비스가 중단됨 😕
- 단순히 장비를 여러 대 증설하면?
- DB 데이터가 분산되어 사용자가 어느 서버에 요청하는가에 따라 다른 결과를 응답함 😕
- 애플리케이션 서버만 다중화하면?
- DB 서버 역시 단일 장애점이 될 수 있음
- 데이터 백업이 되지 않은 경우에는 서비스 가치 및 신뢰에 큰 손해 😕
- 보통 DB Replication으로 극복
- e.g. 서버를 1대로 구성한다 하면?
- 성능
- 3가지 지표
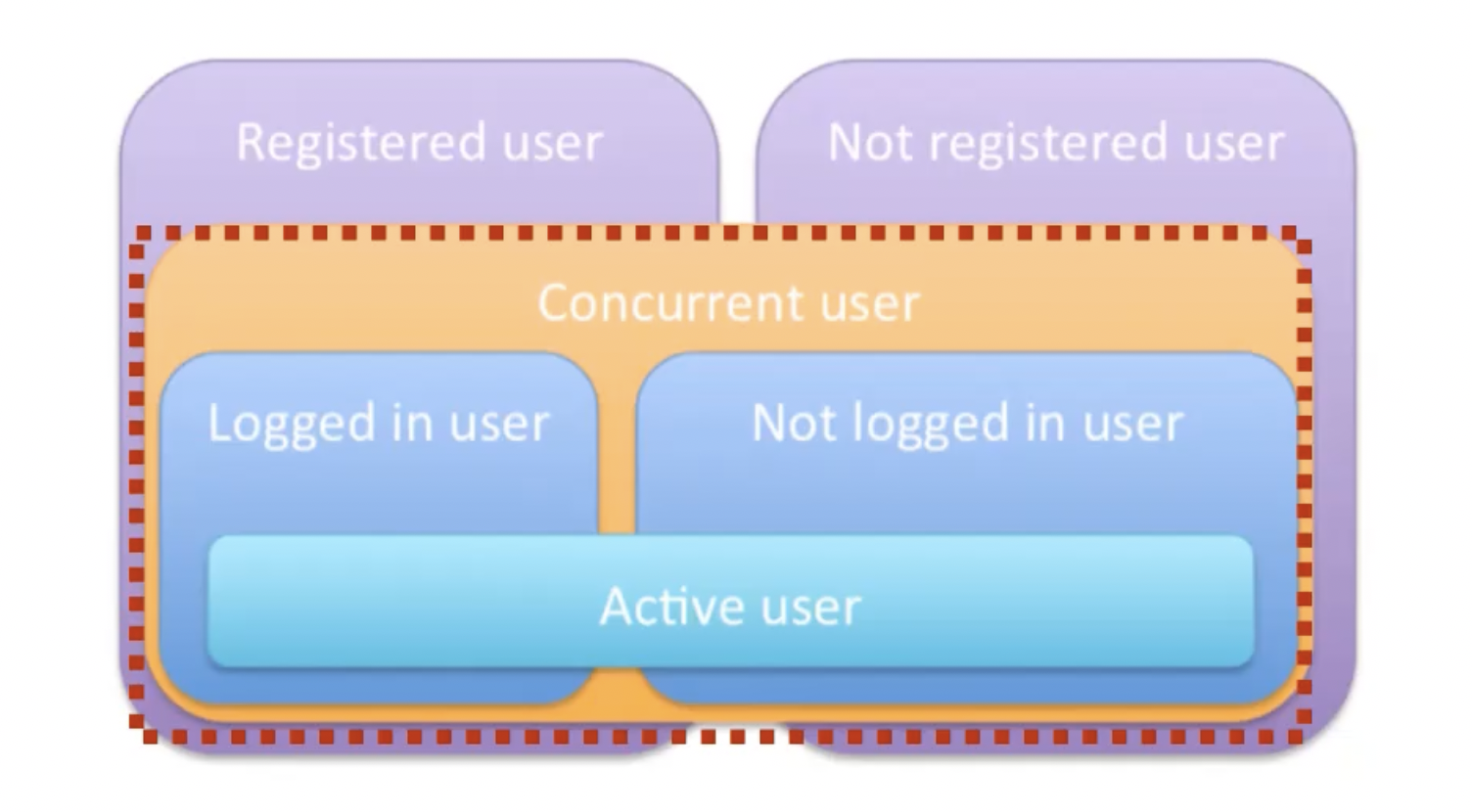
- Users
- 얼마나 많은 사람들이 동시에 사용할 수 있는지
- 시스템 관리자 입장에서는
등록된 사용자 / 등록되지 않은 사용자가 존재 - 서버 관점에서는
로그인한 사용자 / 로그인하지 않은 사용자가 존재 - 성능 테스터 관점에서는
Concurrent User / Active User(≒ VUser)가 존재- Concurrent User? 그냥 connection이 연결되어 있는 User
- Active User? 계속해서 뭔가 요청하는 User (e.g. GET 요청)

- TPS
- 일정 시간 동안 얼마나 많이 처리할 수 있는지 (단위 시간 동안 처리량)
- 처리량
- 스케일 업, 스케일 아웃
- 둘 다 처리량을 증가시킴
성능에 문제가 있는 경우- 1명의 사용자만 사용하고 있는데도 성능이 느림 👉 단일 사용자에 대한 응답 속도가 느림
- 스케일 아웃을 해도 개선 X
- 스케일 업을 하거나, 프로그램을 개선하거나, DB 조회를 개선하거나 등
확장성에 문제가 있는 경우- 당장에는 이슈 X
- 요청들이 엄청 몰려와서 부하가 증가했을 때, 처리하지 못하고 대기하는 요청들이 생김 (포화 상태) 👉 응답 속도가 느려짐
- 스케일 아웃을 해서
부하 분산을 하는 게 필요함
- 스케일 업, 스케일 아웃
- Time
- 서비스가 얼마나 빠른지
- 시간도 여러 종류가 있음
- 사용자에게는
응답 시간만 존재
- 사용자에게는
- 서버 개선
- 서버의 리소스 문제
- 프로그램 로직상의 문제
- DB 또는 다른 서비스와 연결 문제
- 부하 테스트 종류
- Smoke Test
- VUser를 1 ~ 2로 구성
- 최소한의 부하로 테스트 시나리오 오류를 검증
- 최소한의 부하 상태에서 시스템 오류가 없는지 확인
- Load Test
- 서비스의 평소 트래픽, 최대 트래픽으로 구성
- 기능이 정상 동작하는지 검증
- 배포, 인프라 변경(스케일 아웃, DB Failover 등) 시 성능 변화 확인
- Stress Test
- 점진적으로 부하가 증가하게 구성
- 최대 사용자, 최대 처리량 등 한계점 확인
- 테스트 이후 시스템이 수동 개입 없이 자동 복구되는지 확인
- Smoke Test
- 부하 테스트 도구
- nGrinder, k6 등
- 어떤 도구를 써도 상관 X
- 시나리오 기반 테스트
- 동시 접속자 수, 요청 간격, 최대 처리량 등 부하 조정이 가능
- 부하 테스트 서버에 대한 스케일 아웃 지원
- 이 3가지를 지원하는지 확인하고 사용
성능 목표는 어떻게 정할까?
- 성능을 측정할 때,
성능 목표를 우선 정해야 함 - 3가지 지표
- DAU(Daily Active Users)
- 피크 시간대 집중률 == 최대 트래픽 / 평소 트래픽
- 1명당 1일 평균 요청 수
- 해당 지표들을 통해 목표로 하는 RPS(Request Per Second)를 계산할 수 있음
목표값 설정
- Throughput
- 1일 평균 RPS ~ 1일 최대 RPS
- 1일 사용자 수(DAU) * 1명당 1일 평균 접속 수 == 1일 총 접속 수
- 1일 총 접속 수 / 86,400 == 1일 평균 RPS
- 1일 평균 RPS * (최대 트래픽 / 최소 트래픽) == 1일 최대 RPS
- 1일 평균 RPS ~ 1일 최대 RPS
- 목표 RPS를 구해야, 이에 맞춰 목표 VUser를 구할 수 있음
- 목표값을 설정하고 나서, Latency는 API 서버의 경우 50 ~ 100ms 정도 되게 구성하길 권장
시나리오
- 테스트 시나리오를 모두 작성할 수는 X
- 4가지 요소
- 해당 요소들에 대해 집중적으로 작성해야 함
- 접속 빈도가 높은 기능 👉
반드시부하 테스트를 해봐야 함!- 메인 화면 등
- 서버 리소스 소비량이 높은 기능 👉 성능이 떨어지면, 사용자 경험이 떨어질 수 있음
- CPU
- 이미지/동영상 변환
- 인증
- 파일 압축 및 해제
- Network
- 응답 컨텐츠 크기가 큰 페이지
- 이미지/동영상 업로드 및 다운로드
- Disk
- 로그가 많은 페이지 👉 Disk I/O 많이 발생
- CPU
- DB를 사용하는 기능
- 많은 리소스를 조합하여 결과를 보여주는 페이지
- 여러 사용자가 같은 리소스를 갱신하는 페이지
- 외부 시스템과 통신하는 기능 👉 테스트가 까다로운 편이고, 테스트 격리가 쉽지 X
- 결제 기능
- 알림 기능
- 인증 및 인가
- 접속 빈도가 높은 기능 👉
- 해당 요소들에 대해 집중적으로 작성해야 함
주의 사항
- 부하 테스트는
실제 사용자가 접속하는 환경에서 진행해야 함- AWS를 사용한다면,
운영 서버와 동일한 환경의 별도 서버를 구성해서 진행
- AWS를 사용한다면,
- 부하 테스트는 webpagetest와 다르게 클라이언트 내부 처리 시간(브라우저 렌더링)이 배제되어 있음을 염두해둬야 함
- API에 직접 요청하는 것이기 때문
- 운영 DB에 있는 데이터 양 == 테스트 DB에 있는 데이터 양
- 외부 요인(e.g. 결제)의 경우에는
시스템과 분리된 별도 서버(Mocking 서버 ?)로 구성해야 함- 객체를 Mocking하면, Http Connection Pool이나 Connection Thread 등을 사용하지 않아 I/O가 발생하지 X
- 동일 애플리케이션에 Dummy Controller를 구성하면, 테스트 시스템의 리소스를 같이 사용하여 테스트 신뢰성이 떨어짐
정리
- 부하 테스트로 현재 시스템이 어느 정도의 부하를 견디는지 확인할 수 있음
- 목표값을 설정하고, 테스트를 진행하고, 테스트 결과를 바탕으로 서비스 성능을 깊게 이해해보자.
Reference
- 우아한테크코스 강의 - 씨유의 성능 진단하기 on Sep 7