
Introduction
깃-들다 블로그에 업로드한 글에 댓글이 달렸다.

구글링을 해봤는데, 적절한 답변을 찾기 어려웠다.
연관 키워드라도 얻고 싶어 씨유조 단톡방에 질문을 했다.
김김과 배럴이 몇 가지 답변을 해줬고, 다음의 두 포스트를 얻었다.
Posts
1.
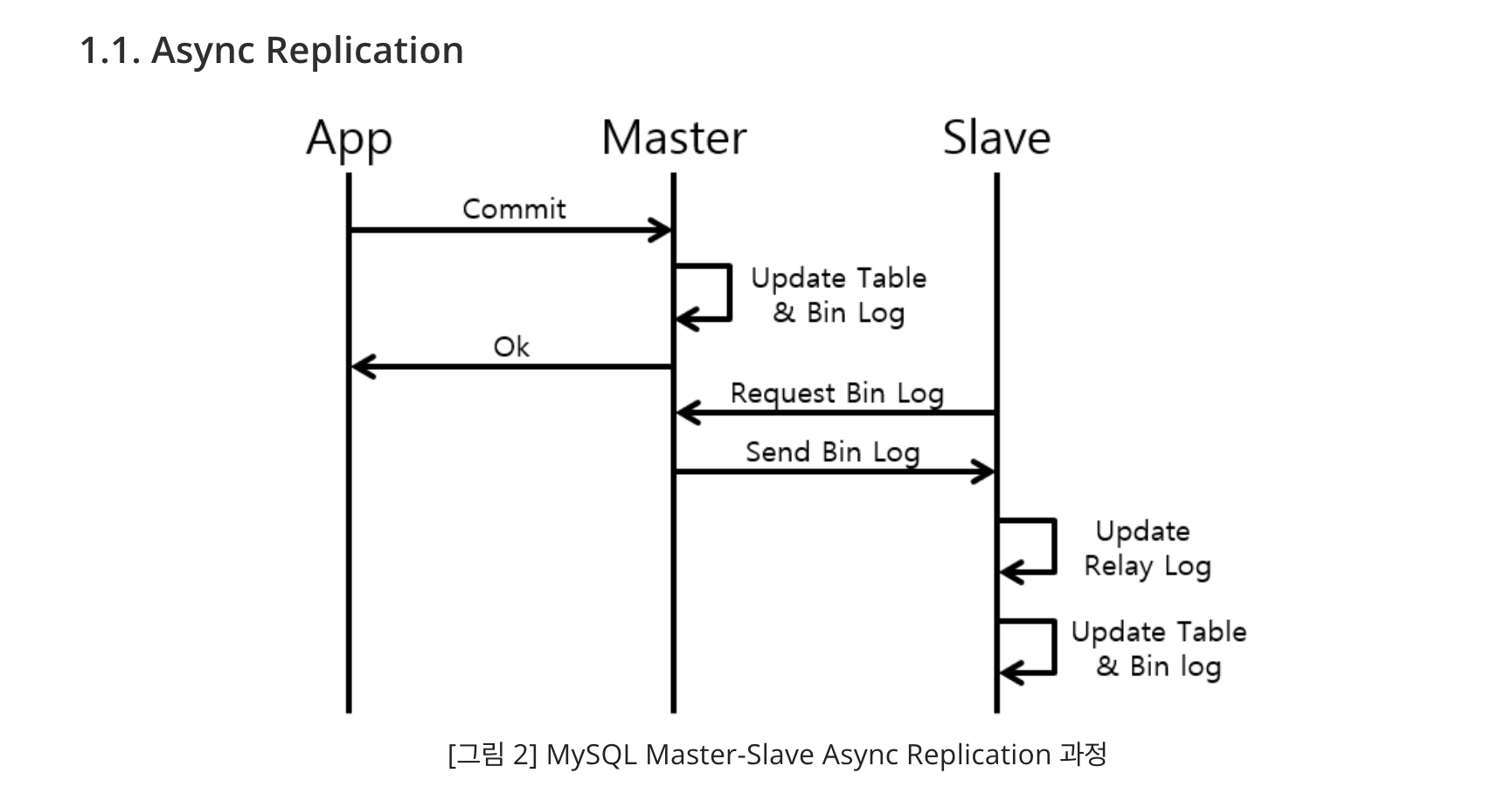
- 표준 비동기 복제(현 상태)는 Master에서 트랜잭션이 끝나면, Slave는 Master binlog를 바탕으로 데이터를 갱신한다.
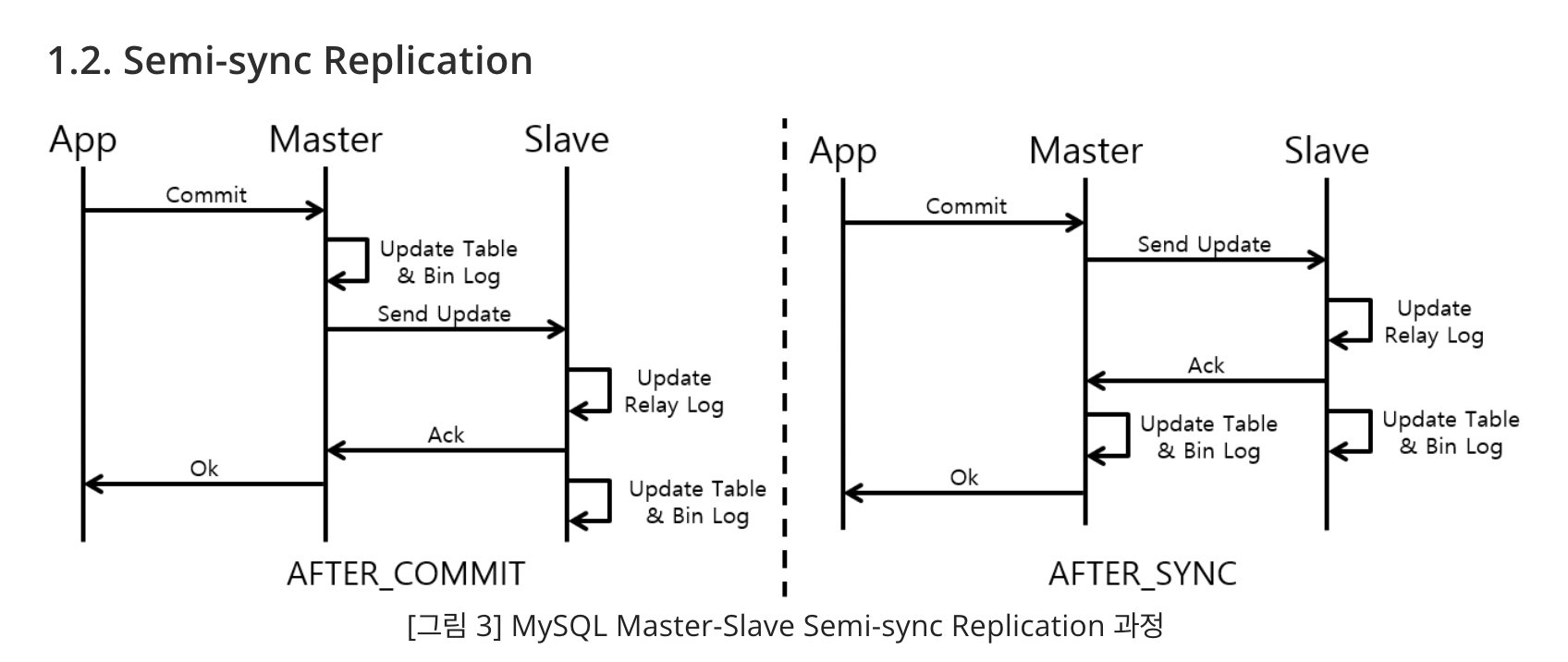
- 준동기 복제는 Master - Slave 사이의 정확한 트랜잭션 전송을 보장하기 위해 서로간의 통신을 한다. Master는 Slave들 중 1개로부터 ACK 신호(트랜잭션을 잘 수신했다는 신호)를 받으면, 그제서야 다음 일을 수행한다. Master에서 Slave로 트랜잭션이 정확하게 복사되는 건 보장하나, Slave에 commit된 것이 실제로 반영됐는지는 보장하지 않는다. 주의해야 할 점은 Master가 특정 세션의 트랜잭션을 처리하기 위해서 Slave들 중 적어도 1개가 ACK할 때까지 또는 timed out에 도달할 때까지 기다린다는 것이다. 결국, 이는 표준 비동기 복제보다 데이터 정합성을 더 가져갈 수 있다. 하지만, Master가 Slave의 응답을 기다리기 때문에 성능에 영향을 미친다.
2.
- 복제 지연 문제는 Master와 Slave가 동기화되기 이전에 읽기 연산이 실행되어 과거 데이터를 조회하게 되는 현상이다. 사용자 입장에서는 데이터가 유실된 것처럼 느껴질 수 있다. 이를 방지하기 위해 read-after-write 일관성이 필요하다. 해당 일관성은 어떻게 지킬 수 있을까?
- 최근 1분까지의 갱신 내역은 Master에서 읽고, 이후 내역은 Slave에서 읽는다.
- 이 방법은 Master에 트래픽이 많이 몰릴 수 있고, 결국 Master가 죽을 수 있다. Master는 단일 장애점이 될 수 있어 위험하다고 판단된다.
- Master의 타임 스탬프를 바탕으로 Slave가 해당 타임 스탬프를 따라잡을 때까지 대기한다.
- 이 방법은 Master가 Slave를 기다려야 해서 성능 이슈를 야기할 수 있다.
둘 다 적절한 해결 방식은 아닌 것 같다.
곧이어 씨유가 나타났고, 포스트를 하나 보내주셨다.
바로 아래의 요것!
3.
- 비동기 복제는 pull 방식, 준동기 복제는 push 방식이다.
- Master와 Slave가 연결되면, Master에는 Dump Thread가, Slave에는 I/O Thread와 SQL Thread가 각각 생성된다.
- Master Dump Thread와 Slave I/O Thread는 연결을 맺고 있다.
- Master Dump Thread를 통해 Slave I/O Thread는 Master binlog를 요청 및 전달받고, 자신의 relay log에 복사한다.
- Slave SQL Thread는 relay log의 내용을 바탕으로 자신의 DB를 갱신하고, 이를 자신의 binlog에 기록한다.
Conclusion
씨유는 준동기 방식을 사용하면 시스템의 불안정성이 더 올라갈 것으로 본다고 하셨다. 그 이유는 Replication은 Command(CUD)와 Query(R)을 분리하기 위한 목적 또는 Master에 문제가 생겼을 때 Slave로 대체하기 위한 목적으로 활용하는데, Master에게 Slave의 상태가 영향을 끼치기 때문이었다. 즉, 주객이 전도되는 상황이 된다.
그래서 나는 지금처럼 비동기 방식으로 처리하고, 데이터 불일치 현상을 다른 방식으로 해결해야겠다고 생각했다. 그리고 부하가 많은 실시간 서비스는 이를 어느정도 감수할 수 밖에 없는 거 같다고 말했다. 이때 씨유가 서비스 운영의 안정성이 우선순위가 더 크기 때문에 일종의 trade-off고, 또한 사용자는 데이터 불일치 현상을 인지하기 어렵다고 말씀하셨다.
따라서, 지금의 비동기 방식을 준동기 방식으로 굳이 변경할 필요는 없다. 서비스 운영의 안정성과 고가용성을 생각하면, 이는 어쩔 수 없는 trade-off다. 데이터 정합성에 문제가 생길 수는 있다. 그러나 사용자는 잘 모른다. 만약 알아도, 화면을 새로고침하는 등의 다른 액션을 취해서 데이터의 갱신을 확인할 것 같다.
한편, 데이터 정합성이 매우 중요한 경우에는 Master에서 Slave 대신 데이터를 조회하도록 처리할 수 있다.